Un billet de blog sans révélation particulière, mais pour mettre bout à bout un ensemble d’éléments rencontrés de nombreuses fois déjà.
La synthèse de l’article ci-dessous se résume à ceci : la porosité des systèmes d’information, qui est au cœur du web de données, entraîne une hétérogénéité des données, dont la solution est le partage d’identifiants partagés, et la condition l’utilisation de classes d’objets communes.
L’ouverture des données des bibliothèques, c’est aussi l’entrée de données exogènes dans le monde des bibliothèques, des données produites par des univers professionnels qui ne pratiquent pas nos règles de catalogage (ils n’en ont pas, ou ils en ont d’autres). Il faut donc pouvoir gérer dans un catalogue une diversité de traitements. Comment « accepter » la diversité ?
- certes, on peut imaginer des reprises, mécanismes d’homogénéisation, manuels, semi-automatiques, par IA, etc. avec toute une diversité de dispositifs existants ou à inventer
- mais surtout si le système est capable d’ingérer de la diversité des métadonnées, cela signifie :
- [des classes] qu’il intègre des « types d’objets » de même nature que ceux connus : appelons-ça des classes. On a besoin de manipuler le même type d’objets que le reste des partenaires (conscients ou non) avec lesquels on échange des données. Là ou une bibliothèque aura trois notices distinctes, Babelio ne va décrire qu’une seule fois le dernier Goncourt, que ce soit en version brochée, en version grands caractères ou en version poche.
- [des identifiants] qu’il est capable de repérer que deux ressources sont une seule et même chose, ou qu’elles sont deux versions de la même oeuvre. Or si la description est différente, comment le peut-il ?
Habituellement, on repère des doublons dans un catalogue au fait que leurs titres, auteur, éditeur, date, soient identiques (en faisant si nécessaire attention à la mention d’édition, à la description matérielle, bref à tous indices supplémentaires qui nous seraient fournis). Mais si les descriptions ne se ressemblent plus ? si les mots ne sont pas dans le même ordre ? Si le titre de série et le titre de volume (pour un manga, par exemple) ne sont pas du tout dans le même ordre, ou dans un ordre aléatoire ?
Ce sont alors les identifiants qui nous sauvent : ce sont les identifiants qui nous permettent de déterminer si deux ressources, quels que soient les autres informations qui les décrivent, sont une seule et même chose. Le nouveau code de catalogage RDA-FR doit être conçu avant tout comme un squelette pour les notices : il décrit une structure, il définit des classes, il détermine les attributs avec lesquels les bibliothécaires vont décrire chaque ressource qu’ils souhaitent décrire.
Et pour éviter à chaque catalogueur des hésitations sur la manière de renseigner tel ou tel attribut (type de contenu, etc.), il fournit des consignes de transcription, des règles d’écriture (« écrire le nom du souverain dans l’ordre naturel »).
Mais ces consignes ne doivent pas faire illusion : en ce sens qu’il ne faut pas croire qu’en les appliquant on aura ainsi un catalogue propre et homogène, avec le même document toujours décrit de la même manière, et donc deux documents proches toujours décrits de la même manière.
Car il est possible que le document imprimé soit catalogué à la main, et l’équivalent numérique importé avec le fichier ePub, et que leurs titres soient bizarrement différents. Mais ce qui importe, c’est qu’on dispose de l’information que leurs ISBN sont reliés par une relation d’homothétie.
C’est cette relation-là qui importe, bien plus que de remettre d’équerre le titre « défaillant ».
Dès lors qu’un catalogue importe des données produites hors d’une bibliothèque, la condition pour que ça marche, ce sont donc les liens entre ressources et non la reprise systématique de ces données (qui relèvera structurellement d’un métier de Danaïde).
(quand je parle ici de récupérer des données, ne pensez pas tout de suite aux descriptions bibliographiques : pensez plutôt aux personnes, aux collectivités, aux lieux, aux événements, qui sont l’objet de descriptions multiples et contextualisées dans tout un tas de bases de données)
Il y a plus d’enjeu à avoir des identifiants partagés, internationaux, pour chaque ressource que nous décrivons, et donc à nous assurer que nous utilisons les mêmes identifiants que ceux dont nous souhaiterions récupérer les métadonnées (ou leur offrir les nôtres), qu’il n’y en a à prétendre infléchir leurs manières de saisir des informations (pour que le nom d’une collectivité soit le même entre notre base et celle de l’INSEE, par exemple).
Ces identifiants ne nous permettront pas forcément d’homogénéiser nos données hétérogènes, mais d’apprendre à mieux vivre avec elles, à construire des systèmes et concevoir des parcours utilisateurs prenant en compte la présence de données hétérogènes.
RDA-FR : entre normalité et normativité

En endossant il y a un peu plus d’un an le rôle de pilote de la normalisation pour la Transition bibliographique, j’ai eu parfois tendance à m’embourber un peu dans la notion même de « norme » (comme document à produire, comme règles à implémenter, etc.).
Au final, cette notion de « norme » ne dit rien du contenu du document qualifié comme tel : quand on affirme que tel document est une norme, on indique qu’il a suivi un certain processus de travail, déterminée par une instance de normalisation (nationale comme l’AFNOR, ou internationale, comme l’ISO ou l’IFLA). Rien de plus.
Par exemple, il existe une norme intitulée Bonnes pratiques pour la prévention, la détection et le traitement des nouvelles cybermenaces – Comment faire face aux stratégies et techniques avancées destinées à nuire, dérober des informations, commettre des fraudes.
Dire ce que ce document est une norme (la Z90-002) ne signifie pas que ce document a une valeur contraignante pour les établissements publics, privés, etc. : cet aspect « contraignant » serait éventuellement assumé hors de la norme elle-même, par des textes légaux (règlements, circulaires, lois) qui font référence à la norme en la déclarant contraignante, recommandée, etc. Mais la Z90-002 est une norme avant que tout texte de loi la rende obligatoire ou pas. C’est une norme parce qu’il y a eu un groupe de travail constitué de manière ouverte, considéré comme représentatif de la communauté professionnelle à laquelle il s’adresse, avec un circuit de validation conforme à ce qu’impose l’AFNOR (enquête publique, etc.).
RDA-FR n’est pas (encore ?) une norme
Notons (mais c’est un peu un détail par rapport au véritable objet de ce billet) que RDA-FR n’a pas le statut de norme : les groupes de la normalisation suivent la méthodologie portée par l’AFNOR, et nous sommes en lien avec un groupe AFNOR (la commission CN46/9), mais à ce jour le code RDA-FR ni aucune de ses parties n’a été enregistré auprès de l’AFNOR avec un ou plusieurs identifiants qui viendraient se substituer aux Z44-050 et consoeurs.
La norme comme recensement de la normalité
Pour reprendre l’exemple de la Z90-002 mentionnée ci-dessus : quels objectifs se donne un groupe de travail qui veut publier un document de recommandations pour lutter contre les cybermenaces (comme celle contre laquelle la British Library lutte depuis plusieurs mois) ?
Son objectif ne va pas être de produire un cadre contraignant, mais de recenser les bonnes pratiques, d’en faire une synthèse et de proposer à la communauté professionnelle concernée un guide dont le statut de norme signifiera : on s’est efforcé de faire le tour de la question en consultant et en associant plein de gens du métier, logiquement le résultat ne pourrait pas être meilleur.
Un tel document recensera donc l’existant, repèrera les traits communs, dégagera des grands principes et des actes concrets. Les membres du groupe viendront contribuer avec leurs propres pratiques, leurs lectures, leurs expériences.
Bref, il mettra par écrit ce qui sera le plus normal, c’est à dire le plus courant, dans la profession, en identifiant les usages pour les décrire de manière utile à l’ensemble de la communauté.
RDA-FR : une norme normative
Le contexte de rédaction de RDA-FR est complètement différent : il n’est pas envisageable de recenser l’existant. On ne peut pas aller voir les bibliothèques qui cataloguent déjà en IFLA LRM, repérer et universaliser les bonnes idées, pour mettre tout ça dans un guide des bonnes pratiques comme on fera une livre de recettes de grand-mère.
La rédaction de RDA-FR ne vise pas à recenser ce qui est normal (au sens de courant), mais se rédige dans une dynamique plus proactive, comme une prophétie auto-réalisatrice : on fait un exercice consistant à imaginer ce qu’on aura besoin/envie de faire dans un futur contexte de catalogage IFLA LRM, pour le mettre par écrit.
C’est cette distinction entre recensement de l’existant vs rédaction d’une future loi que je désigne (sans doute en torturant les termes) par : normalité vs normativité.
Conséquences pour la suite
Ce constat n’est pas une critique : je ne vois pas comment il aurait pu en être autrement (sauf à attendre que les choses évoluent toutes seules et à lancer la rédaction d’une telle norme vingt ans plus tard, en regardant un peu comment les établissements avaient réussi à se dépatouiller entre temps #beurk).
Néanmoins identifier cette distinction entre ce qu’est une norme habituellement, et le contexte de travail de RDA-FR, permet :
- potentiellement de comprendre certaines difficultés dans la rédaction : c’est long d’inventer le monde de demain !
- d’anticiper les conséquences du texte produit pour la suite : il n’émane pas des pratiques de catalogage en vigueur, il prétend les déterminer.
Pour autant, il n’a jamais été mis en application de manière littérale et intégrale.
Donc il est indispensable de prévoir une période de mise à l’épreuve du feu : il me semble inévitable que ce code de catalogage doive être réévalué après les premiers mois/années pour être ajustés, en fonction d’écueils constatés lors de sa mise en œuvre.
Corollaire : les ajustements (non encore identifiables aujourd’hui, mais dont l’existence future est un principe que l’on pourrait valider maintenant) doivent venir de la mise en œuvre du code, et non de sa relecture. L’objectif n’est pas de perfectionner le code par rapport à lui-même (on le relit, et on trouve qu’il y a des choses qu’il faudrait dire autrement, préciser, amender, etc.) mais par rapport à ses utilisateurs (ils s’en servent, et remontent les problèmes). Donc il faudra s’interroger sur le bon circuit pour les remontées des problèmes, et des instructions pour décider de les prendre en compte (identifiés comme structurels) ou non.
Autre stratégie possible : on laisse le code en l’état pendant les premières années, et quelque part entre N+5 et N+10, on demande aux établissements : « Alors, qu’est-ce que vous n’avez pas réussi à faire ? Qu’avez-vous été obligés de contourner ? Qu’est-ce qui vous rend malheureux — ou si énervés ? » (cette deuxième démarche permet d’éviter d’avoir une coupure entre des groupes de rédaction de la norme et des groupes d’intégration des remontées des problèmes : coupure qui donnera le sentiment, légitime, que la phase de « normalisation » est terminée).
Troisième fois que j’essaie d’apporter une proposition de réponse, même partielle, à ce billet. A chaque fois je m’embarque dans des précisions complémentaires, qui me semblent indispensables. Puis je m’interromps afin de reprendre plus tard — et je perds le fil. Donc changement de méthode : je rédige un billet plus court, d’une traite, et je complèterai peut-être ultérieurement par d’autres billets.
En gros, 3 axes essentiels :
- Les notices actuelles sont des documents
- Une fois la définition d’une entité rédigée, on ne peut plus choisir arbitrairement les métadonnées qu’on veut lui attribuer
- Les relations disposent aussi de métadonnées
Les notices bibliographiques et d’autorité sont des documents
Une notice bibliographique comportera ainsi tout un tas d’informations utiles sur le prix, l’auteur, le résumé. Une notice d’auteur contiendra des dates de naissance et de mort, la liste des pseudonymes successifs de l’auteur, ses éventuels ORCID et ISNI, etc. Une notice de lieu pourra contenir la date de fondation du lieu, ses différents noms successifs (et leurs dates d’utilisation) — ou au contraire ne contenir qu’un seul nom si l’on considère qu’on a besoin d’une notice distincte par nom (Istanbul / Constantinople / Byzance, ou Istanbul-Byzance-Constantinople).
S’il est jugé pertinent d’y rajouter d’autres infos, rien ne l’interdit : il suffit d’ajouter de nouvelles zones. Par exemple les notices IdRef sont enrichies (à l’affichage et non en production) d’éléments extérieurs : cela signifie qu’il a été considéré utile, voire nécessaire, d’ajouter pour les utilisateurs des informations non utiles pour le catalogueur (ou déjà saisies ailleurs, mais utiles pour les deux).
La description d’une entité est plus contraignante
Une fois que vous avez défini ce qu’est une personne, vous ne pouvez pas y ajouter les métadonnées qui vous arrangent.
Par exemple, tout n’est pas associé à la personne (en tant qu’être humain) dans les informations suivantes :
- 1918 : Date de naissance de Romain Gary
- 27/07/2023 : date de dernière modification de la notice
- 1956 : date du prix Goncourt remporté (pour Les Racines du Ciel)
- 1974 : date de première utilisation du pseudonyme Emile Ajar (avec Gros-Câlin)
Dans une notice d’autorité, les 4 informations se trouveront dans 4 zones distinctes (zone codée ou zone de note biographique, par exemple). Mais dès lors qu’on prétend décrire la Personne Romain Gary, on est obligé de modéliser (faire des schémas) pour comprendre à quoi se rattachent chaque information. Car si l’on veut ensuite exprimer toutes ces informations en RDF, il est exclu de déclarer les triplets suivants :
<ID_RomainGary> <est> "une personne"<ID_RomainGary><s'appelle> "Romain Gary"<ID_RomainGary> <a comme date de naissance> "1918"- <ID_RomainGary> <a comme date de dernière modification> « 20230727 »
- <ID_RomainGary> <a comme date de prix Goncourt> « 1956 »
- <ID_RomainGary> <a comme date de première utilisation du pseudonyme Emile Ajar> « 1974 »
Seuls les 3 premiers sont corrects.
Il faut donc se demander quel sera le sujet et le verbe dont la valeur sera « 230727 », « 1956 » et « 1974 », et comment je rattache ces informations à la personne qu’était Romain Gary.
Par exemple (et je ne traiterai que cette info là), on va avoir besoin d’exprimer une relation entre Romain Gary et son pseudonyme.
<ID_Romain_Gary> <utilise comme pseudonyme> <ID_pseudoEmileAjar><ID_pseudoEmileAjar><a comme valeur> "Emile Ajar"<ID_pseudoEmileAjar><a comme date de première utilisation> "1974"
Je m’empresse de préciser qu’en format de catalogage MARC, ce ne serait pas forcément plus long à saisir. Mais l’administrateur du format, et la personne chargée de convertir ces informations de notice en données exposées vers l’extérieur (car c’est bien le but de la Transition bibliographique : exposer nos données vers l’extérieur, et non plus seulement des notices), vont devoir clarifier le positionnement de chaque zone au sein d’une architecture explicite de l’information (un schéma global).
Les relations ont elles aussi besoin de métadonnées
Les entités sont ce qui nous préoccupe le plus au premier abord : il faut les décrire, les qualifier, elles nous permettent de décrire nos ressources.
Mais on se rend compte assez rapidement que dans de nombreux cas, certaines métadonnées présentes aujourd’hui dans nos notices se rattachent en réalité non pas aux entités (ou aux ressources qu’on pense décrire), mais aux relations entre deux entités.
Par exemple on trouve dans la notice du journal L’Humanité du catalogue de la BnF la ligne suivante :
Jaurès, Jean (1859-1914). Directeur de publication, 1904-1914
Pour les règles de catalogage actuelles, on a juste à donner les consignes suivantes : mention de responsabilité en zone 700, code fonction en $4, précisions en $7 (pardon, c’est de l’Intermarc BnF, et ça veut dire ici : « précisions complémentaires »). Et l’internaute comprend (j’espère) qu’il s’agit des dates extrêmes où Jean Jaurès fut directeur de publication de ce journal.
Dans un environnement où on décrit des entités et des relations, à quoi se rapporte cette période 1904-1914 ? A la relation
<ID_Humanite> <a comme directeur de publication> <ID_JeanJaurès>
De même, le code fonction « Auteur incertain » qui constitue une relation entre une œuvre et une personne, par exemple, est une métadonnées « information incertaine » qui affecte cette relation, et non une information ni sur l’œuvre ni sur la personne.
Conclusion
Un gros travail dans la rédaction du code RDA-FR, de l’ontologie qui l’accompagne désormais, et de la manière dont on construit un format (y compris un format MARC, comme Intermarc NG ou Unimarc ER) de catalogage pour décrire ces entités et leurs relations et leurs règles de conversion, est donc consacré à s’assurer que les attributs sont posés aux bons endroits, sur les bonnes entités, qu’elles qualifient réellement ce qu’on prétend leur faire qualifier.
Je n’irai donc pas plus loin pour le moment, de peur qu’en étant plus ambitieux je ne termine jamais ce billet. J’espère vous laisser frustré plutôt qu’indifférent (mais je vais éviter de poser la question frontalement). C’est donc évidemment très incomplet (il y a ce que j’omets pour l’instant, il y a aussi ce que j’ignore et n’ai pas identifié).
Je n’ai pas oublié les questions posées dans mon dernier billet de blog (mais une réponse est belle et bien prévue, sinon planifiée). B
Mais mes lectures d’été m’ont donné l’occasion de me replonger dans le rapport du groupe Normalisation de la Transition bibliographique publié en 2021 sur l’analyse de RDA : en effet une première version de RDA est parue en 2010, avant que ne soit conçu le modèle IFLA LRM (2018), synthèse des 3 modèles FR*. En 2018 a été lancé le projet « 3R » de refonte de RDA. Suite à cela, le groupe Normalisation de la Transition bibliographique a présenté en 2021 au CSB (ministères ESR et Culture + agences bibliographiques) un rapport analysant le code RDA refondu, et requestionnant la trajectoire de RDA-FR (code indépendant ou profil d’application de RDA ?).
Les conclusions du rapport ont conforté la stratégie française (je vous laisse éventuellement vous référer aux conclusions et arguments de ce rapport), mais pour ma part je voulais donner à lire ici quelques lignes qui sont dans la première partie et relèvent d’un rappel du contexte :
Avec le web de données, c’est une nouvelle conception de l’interopérabilité qui s’impose, avec une transition depuis un monde où l’on normalise des notices pour se les échanger vers celui où l’on structure les données pour se les partager, avec l’émergence du rôle clé de la modélisation et de l’organisation par entités. Le pivot du partage des données n’est donc plus la manière dont une instance d’entité est décrite (par un point d’accès privilégié censé être commun pour tous au niveau international, par exemple) ; mais il repose sur un identifiant désignant de manière explicite, pérenne et univoque, une instance dont les modalités de description sont renvoyées à la responsabilité des communautés nationales ou transnationales. […] C’est une interopérabilité qui n’intervient plus au niveau du catalogage courant mais au niveau des machines et des moteurs de recherche. Les identifiants internationaux (par exemple : ISSN, ISBN, ISNI, ISAN…) permettant des alignements entre graphes sont donc les leviers principaux de cette interopérabilité d’un genre nouveau pour qui l’importance du catalogage partagé est moindre que la nécessité d’une gestion partagée et normalisée d’identifiants.
On attend aujourd’hui d’un code de catalogage qu’il nous fournisse des règles permettant de garantir que tout le monde saisit les informations « de la même manière ». Mais en passant d’ISBD à RDA/RDA-FR, l’accent n’est plus mis sur la même chose. Dans l’univers ISBD, on se préoccupe des règles de description pour que 2 catalogueurs transcrivent bien la zone de titre, ou la description matérielle, de la même manière : ainsi les notices se ressemblent d’un catalogue à l’autre, on peut donc partager la production de notices en sachant, à l’import, qu’on ne verra pas arriver des notices extérieures complètement différentes.
RDA et RDA-FR se préoccupent d’autre chose : proposer un cadre de description commun, une architecture commune, permettant d’avoir de part et d’autres des entités de même contour. La transcription de chaque élément d’information importe moins1. Le pré-requis essentiel est qu’on puisse aligner des entités entre bases, et pour cela partager des contours communs : qu’un « livre » dans une BDD corresponde à une « manifestation » dans une autre (peu importe l’appellation de l’entité), mais qu’il partage bien la même liste d’attributs autorisés pour sa description. Ainsi, Wikidata ne partage pas le même modèle (ce n’est pas la même liste d’entités) que IFLA LRM, ce qui d’emblée pose des questions d’articulation (par exemple dans Wikidata, Le mystère de la chambre jaune existe comme literary work, qui est une sous-classe de Work au sens Wikidata ; et il existe à côté de ça Le mystère de la chambre jaune (1932, Laffitte) qui est de type version, édition ou traduction : je vous laisse réfléchir aux alignements entre ces 2 entités Wikidata et les entités LRM qui pourraient exister, en face, dans un catalogue de bibliothèque).
Aujourd’hui, les SIGB sont conçus pour dériver des notices (Z39.50, here we are), mais les mécanismes d’injection d’éléments d’information ne sont pas aussi « natifs » : des fonctionnalités sont éventuellement prévues pour venir faire des enrichissements par lots, mais potentiellement en une succession d’étapes à concevoir à chaque cas.
Un environnement avec IFLA LRM et RDA (ou RDA-FR) n’a de sens que si les fonctionnalités de manipulation des informations qui s’y trouvent facilitent les enrichissements, ajouts, corrections, curation, au niveau de chaque donnée — chacune étant associée à un identifiant (généralement local, mais aligné à un identifiant international) permettant de désigner l’entité décrite (OEMI, Agent, Concept, etc.).
On peut commencer à se demander comment se passera la dérivation des notices (çàd un ensemble d’informations relatives à une entité). Mais il ne faudrait pas passer à côté du changement de paradigme induit par le passage à un système utilisant LRM : un des intérêts doit être de faciliter la récupération de bouts d’informations.
Par exemple vous avez une source primaire de données, mais vous pouvez aller récupérer plus facilement des prix littéraires associés aux oeuvres ou aux auteurs, des affiches de films, etc. dans des sources d’informations exogènes au monde des bibliothèques, qui ne parlent pas le même format que nous — mais parce que nos données sont désormais pensées granulairement, et qu’enrichir 10.000 notices pré-existantes d’une ou deux informations doit avoir le même niveau de complexité qu’importer un panier d’Electre, de Moccam ou de la BnF.
1 Je ne sais pas si c’est le motif d’origine, mais j’y vois personnellement un principe de réalité, sur le fait que les données des bibliothèques doivent pouvoir coexister avec des données de tout un tas d’autres acteurs. Cela signifie notamment qu’on peut être amenés à importer dans un catalogue des notices de collectivités ou de personnes émanant de l’univers des majors, ou des maisons de production cinématographiques : et qu’on ne maîtrisera pas la manière dont ils choisissent de transcrire certaines informations. En revanche on peut s’assurer qu’on parle bien de la même chose : qu’un « film » d’un côté est une oeuvre (ou une expression ou une manifestation) chez nous, pas exemple.
Pour l’instant, je fais juste un billet pour poser la question. J’ai quelques propositions d’éléments de réponses, mais très incertaines.
En tout cas j’ai le sentiment d’avoir entendu cette expression comme un mantra depuis plusieurs années (« Désormais, avec IFLA LRM, on va cataloguer dans un univers entités-relations »), mais sans que les implications en soient explicitées.
Et honnêtement, l’article Wikipedia ne m’aide en rien (mais ce n’est pas sa faute) : le modèle entités-relations est une manière de concevoir et représenter l’information. Mais qu’est-ce que ça change pour un catalogueur ? Pour un concepteur d’interface de catalogue (versants pro et perso) ? Pour un utilisateur et un réutilisateur des données produites par les bibliothèques ?
Si vous voulez proposer des trucs en commentaires, c’est ouvert (mais je sais que les commentaires, c’est so 2008). Sinon, je vous laisse cogiter de votre côté.
En réfléchissant un peu en boucle à un mail reçu, j’ai réalisé que, à titre personnel, j’avais pris complètement à l’envers la question de l’évolution des catalogues (comme interface publique) dans la perspective de la Transition bibliographique.
Depuis plusieurs années, je crois que la question qui nous est posée est : comment allons-nous faire évoluer nos catalogues dès lors qu’ils contiendront des données LRMisées (ou FRBRisées, si vous avez été formés à la question avant 2017) ?
C’est une très mauvaise démarche : vous partez des données pour essayer de définir l’affichage idéal, la navigation adaptée à ces données, etc.
En réalité, la bonne question est : quelles interfaces j’ai envie de construire pour mes lecteurs, que la Transition bibliographique rend possibles (ou : « …. que des données LRMisées rendent possibles ») ?
Qu’est-ce que la Transition bibliographique ?
Flûte, j’ai un peu trop tendance à poser sans cesse cette question (à quelques variantes près). Je me justifierai en disant que ce n’est pas une question d’incompréhension mais de temporalité : l’avancée des travaux, autant que leurs retards par rapport à la planification initiale, justifie une actualisation du discours.
Voici une triple proposition d’orientations :
- exposer ses données sur le web
(le RDF étant la technologie identifiée, mais non limitatrice) - implémenter le modèle LRM dans les catalogues (et, ce faisant, le code de catalogage RDA-FR est ce qui rend cette implémentation possible)
- rend poreux les catalogues de bibliothèques, et circulables les données entre catalogues et toutes autres bases de données (internes à un même établissement, et au-delà bien sûr)
le maître-mot, ici, est l’interopérabilité
Chacune de ses orientations est à la fois cause et moyen des deux autres.
Faire évoluer son catalogue de bibliothèque : pourquoi faire ?
La Transition bibliographique est censée être une réponse à des problèmes anciens, pas la source de nouveaux problèmes (bon, de fait… mais quand même, on va partir de là — et puis, pour ce que j’ai à en dire, ça fait sens).
Les catalogues de bibliothèques sont hérités des catalogues sur fiches, eux-mêmes hérités des catalogues imprimés (vraisemblablement hérités des catalogues sur volumen, mais je vais m’arrêter là). Donc quand on administre un OPAC et qu’on envisage des services dans un environnement en ligne, on se trouve limité dans les services qu’on arrive à rendre à ses lecteurs :
- critère d’identification du bon document
- sélection d’ouvrages
- recommandation (plus ou moins personnalisée)
- mauvaise gestion du bruit comme du silence
Donc il faut repartir de son catalogue actuel et de ses frustrations (surtout des frustrations !), pour envisager les évolutions souhaitées — et non partir d’un catalogue organisé en oeuvre-expression-manifestation-item pour se demander ce qu’il convient d’en faire.
En quoi la Transition bibliographique est une réponse ?
En tant que telle, la Transition bibliographique n’est pas une réponse technique directe aux problèmes qu’on peut se poser. Mais disposer prochainement d’un catalogue composé d’entités et de relations entre elles devrait être la condition des réponses possibles.
- Tout est modulable : les données permettent potentiellement d’obtenir une liste d’ouvrages à partir du pays ou de la date de naissance de l’auteur, ou la liste des pays ou dates de naissance d’auteurs à partir d’une thématique précise.
- Les enrichissements venant du monde extérieur sont facilités : l’adoption d’identifiants universels, ou le partage d’identifiants, leur transmission entre univers distincts et leurs alignements (monde de l’édition, lecture publique, ESR, producteurs de streaming, etc.), l’articulation avec des ressources complémentaires en ligne, tout un tas de choses du même genre est facilité
Plus largement, en théorie, toute information présente dans la base peut servir de point d’entrée à quelqu’un qui y lance une recherche, et peut lui permettre d’extraire une série d’informations dans le format qui lui convient le mieux.
La Transition bibliographique ne doit pas devenir le problème
Concevoir une interface signifie faire des choix : déterminer le parcours utilisateur, les services qu’on souhaite lui proposer. J’ose espérer que si une bibliothèque n’achète pas tout ce qui sort en librairie, ce n’est pas seulement pour des raisons de moyens. La bibliothèque se destine à un territoire, à un public, elle construit son offre de services.
De même, une interface n’est pas là pour rendre compte de la modularité absolue (en théorie) des données que stocke la base de données : elle se détermine en fonction de ses utilisateurs et des services qu’on souhaite leur rendre.
Donc dans la réflexion à mener sur l’évolution (encore largement à venir, et — surtout — jamais terminée) des interfaces des catalogues, il faut plutôt re-débrider son imagination sur ce qu’on aimerait, à travers un catalogue (mais est-ce encore un catalogue ? ou des modalités d’accès aux services culturels d’une bibliothèque et à ses collections). Et voir si la trajectoire de la Transition bibliographique permet de mieux y répondre.
Tout cela n’est peut-être pas une révélation pour vous ?
Et bien je vous en félicite !
Pour ma part, j’ai le sentiment de m’être demandé ces dernières années : « Alors, comment on pourrait afficher les œuvres, les expressions et les manifestations au sein d’une même interface, avec une navigation fluide et qui rende service au lecteur ? ».
Alors qu’en fait il n’y a pas lieu de lui afficher (de lui infliger ?) les œuvres, les expressions et les manifestations, mais de lui afficher les informations qui lui sont utiles pour une navigation la plus efficace et agréable possible. Et, pour cela, de bénéficier d’une structuration souple, et facilement enrichissable, des données qu’on interroge.
Pour moi, je vais essayer de faire en sorte que ça change les choses, au moins dans mon esprit. En effet je réalise (un peu tardivement !) que dans mes expérimentations autour de 340 notices Unimarc d’entités LRM, la question que je me posais était systématiquement celle du dessus.
Voyons si la prise de conscience (ou ce que je prends pour telle) décrite dans le présent billet me permet d’obtenir des orientations différentes ?
Découvrir RDA-FR avec ChatPDF
Très égoïstement : tandis que d’autres explorent les potentialités de ChatGPT pour construire de nouveaux services aux usagers, j’essaie de voir comment il va me simplifier la vie. A moi, dans mon petit quotidien de tous les jours, composé de réunions, de lectures et d’écritures (de code, de comptes-rendus, de notes, etc.).
Humble retour d’expérience, venant tout juste de faire la découverte de cet outil, ChatPDF, grâce à ce tweet.
ChatPDF est un outil en ligne qui fonctionne comme ChatGPT, sans authentification nécessaire, et avec un modèle économique en mode freemium : gratuit si le PDF fait moins de 200 pages. Il y a également une limite de 3 PDF par jour.
La procédure est simple : on charge le PDF, petit texte renvoie la thématique du document et suggère déjà quelques questions — et ensuite vous explorer le contenu comme vous le voulez.

Notez qu’au lieu de charger un PDF, il est possible de mentionner son URL, par exemple celui du chapitre 9 sur les personnes et identités publiques de personnes, qui a été soumis à enquête en ce début d’année 2023.
C’est ce que j’ai fait, et voici le fruit de l’échange :
Chat with RDA-FR-chapitre-9-enquete2022.pdf
Qu’est-ce que la transition bibliographique et comment est-elle liée à la section 3 de la transposition française de RDA ?
Qui sont les membres du groupe de travail « Noms de personne et de famille » et quel est leur rôle dans la transposition française de RDA ?
Comment la section 3 de la transposition française de RDA peut-elle aider les bibliothèques et les centres de documentation à mieux identifier et décrire les personnes, les familles et les collectivités dans leurs collections ?
Comment sont définies les personnes et les identités publiques, et quelle est la différence entre les deux ?
La page 5 de la transposition française de RDA explique que chaque personne a au moins une identité publique, et qu’aucune identité publique ne peut exister sans être associée à une personne ou à un agent. Les identités publiques peuvent être multiples ou uniques, et sont clairement désignées en tant que telles. Les attributs relatifs à la personne et ceux relatifs à l’identité publique sont clairement distingués. En d’autres termes, une personne est une entité individuelle, tandis qu’une identité publique est une représentation publique de cette personne qui peut inclure des informations telles que son nom, son adresse, son numéro d’identification, etc.
Quels sont les principaux attributs d’une personne ?
La page 58 de la transposition française de RDA explique que les attributs d’une personne peuvent être exprimés sous forme d’une relation vers un référentiel. Certains de ces attributs peuvent également être fictifs, notamment les lieux et les langues. Cependant, la transposition française de RDA ne fournit pas une liste exhaustive des attributs d’une personne. Les attributs peuvent varier en fonction du contexte et des besoins spécifiques de chaque situation.
Quels sont les principaux attributs d’une identité publique ?
La transposition française de RDA ne fournit pas une liste exhaustive des attributs d’une identité publique. Cependant, la page 5 explique que les attributs relatifs à la personne et ceux relatifs à l’identité publique sont clairement distingués. Les identités publiques peuvent inclure des informations telles que le nom, l’adresse, le numéro d’identification, etc. La page 58 ajoute que ces attributs peuvent être exprimés sous forme d’une relation vers un référentiel et que certains de ces attributs peuvent également être fictifs, notamment les lieux et les langues. Les attributs d’une identité publique peuvent varier en fonction du contexte et des besoins spécifiques de chaque situation.
Comment décrire un pseudonyme collectif ?
La transposition française de RDA explique que pour décrire un pseudonyme collectif, il faut utiliser l’attribut « Catégorie » et choisir « Pseudonyme collectif » dans la liste des natures de nom. Un pseudonyme collectif est un nom de personne choisi par un groupe de personnes dans le but de dissimuler au public leur existence à titre individuel ou leurs noms réels respectifs. La page 14 fournit également des exemples de pseudonymes collectifs, tels que « Pierre Schumann Audrycourt » et « Irene Adler ».
L’attribut « catégorie » est un attribut de personne, ou un attribut d’identité publique de personne ?
L’attribut « Catégorie » est un attribut d’identité publique de personne. La page 5 de la transposition française de RDA explique que les attributs relatifs à la personne et ceux relatifs à l’identité publique sont clairement distingués. L’attribut « Catégorie » est utilisé pour préciser la nature du nom sur lequel est fondée l’identité publique, et doit être choisi parmi les options suivantes : Nom réel, Pseudonyme ou Pseudonyme collectif.
Comment traiter les personnes fictives ?
La transposition française de RDA fournit des instructions pour traiter les personnes fictives. La page 58 explique que les personnes fictives peuvent être décrites en utilisant les mêmes éléments que pour les personnes réelles, mais en précisant leur nature fictive. Les attributs tels que le nom, la date de naissance, le lieu de naissance, la nationalité, etc., peuvent être utilisés pour décrire une personne fictive. Cependant, il est important de préciser qu’il s’agit d’une personne fictive et de fournir des informations sur l’œuvre ou le contexte dans lequel elle apparaît. La page 59 ajoute que les personnages fictifs peuvent également être décrits en tant qu’entités distinctes avec leurs propres attributs et relations.
Pour le nom d’une personne, dois-je plutôt écrire : « XIV, Louis », ou « Louis XIV »
La page 28 du fichier PDF fournit des exemples de noms de personnes, y compris les noms de souverains. Selon ces exemples, le nom « Louis XIV » est correctement écrit dans l’ordre courant du prénom suivi du nom de famille. Par conséquent, il est préférable d’écrire « Louis XIV » plutôt que « XIV, Louis ».
La compréhension globale du document est faussée par les pages liminaires du chapitre, qui se calent sur l’ensemble du code en mentionnant la section dont le chapitre fait partie (les agents) alors que le texte analysé ne porte ensuite que sur les personnes.
Par ailleurs, étant donné le contenu qui est analysé (uniquement le chapitre chargé), l’outil sera incapable par exemple de pointer les différences avec les règles antérieures puisque celles-ci ne sont pas précisées.
Néanmoins ça fait un outil peut plus interactif et — j’ose le mot — ludique pour découvrir les chapitres de RDA-FR. Car quand nous annonçons un nouveau chapitre, avec une enquête transmise à la communauté des collègues, tous potentiels relecteurs, l’idée d’ouvrir un code de catalogage, comme ça, au débotté, peut paraître intimidant, ou vain.
Alors pourquoi ne pas tester cet outil sur un autre chapitre, et lui poser toutes sortes de questions ? Ça tombe bien, il y a une autre enquête en cours, sur le chapitre concernant les lieux. Sinon, vous pouvez aussi découvrir le chapitre 4 (Acquisition et accès à la manifestation) pour voir de cette manière plus exploratoire ce qui peut bien se trouver dedans !
Re-précision : je viens tout juste de découvrir l’outil, je ne mesure pas du tout sa capacité à rester fidèle au contenu et à ne pas générer d’erreur ou de fausse interprétation. En revanche si vous envisagez d’évaluer l’outil lui-même (en plus des chapitres RDA-FR), ça m’intéresse !
Addendum
Dans la foulée, j’ai découvert et testé Ask your PDF, qui se positionne sur les mêmes fonctionnalités. Mais apparemment il n’a pas bien compris le contenu du chapitre 16 sur les lieux.

Cf. les 2 billets précédents :
- 340 notices en Unimarc LRM. 1 : Intentions et méthodologie
- 340 notices en Unimarc LRM. 2 : Les oeuvres
Le jeu de données est présenté dans ses deux billets, mais surtout sur Zenodo, à travers la « communauté » créée par le groupe Systèmes et Données de la Transition bibliographique (çàd regroupement de publications/jeu de donneées/docs divers ayant le même centre d’intérêts) :
- Jeu de notices en UNIMARC conforme au modèle IFLA LRM – documentation
- contenant notamment la liste des référentiels utilisés
- Liste des zones UNM/A dans les notices d’oeuvre et d’expression
Mais quoi qu’il en soit, il est très difficile de comprendre ce qu’il y a dans ce jeu de données et de le manipuler, de se l’approprier. Les graphes sont un certain mode d’approche, mais au-delà d’un effet de curiosité, je ne suis pas sûr que nos cerveaux y soient suffisamment habitués (sur d’autres contextes) pour que ça fasse vraiment sens.

La vraie manière dont nous nous approprions habituellement un ensemble de notices, c’est sous forme de liste de résultats + notices détaillées.
C’était précisément l’objectif de cette série de billet (ce 3e billet n’en est pas pour autant le dernier) : arriver à reproduire des pages de résultats et affichages détaillés appliqués à ce jeu de données en Unimarc entités (il a été suggéré en journée de groupes Transition bibliographique d’éviter l’appellation « Unimarc LRM » — je ne rentre pas dans les détails ici).
J’aurais beaucoup de choses à vous en dire, mais je me rends compte de vouloir toutes les énoncer en amont retarde la publication de ce billet, et la diffusion de ces listes de résultats. J’ai vite pris conscience qu’il fallait prendre certaines décisions (donc renoncer à des possibilités) pour commencer à construire une navigation. C’est collectivement qu’il faudrait reprendre toutes ces décisions, en réalité.
Vous avez deux modalités pour constater l’avancement de mes expérimentations
Notebook Affichage des résultats
Le notebook génère et emmagasine les notices, puis lorsque vous faites une recherche par mots, il va créer des pages HTML de résultats correspondants, permettant en parallèle de naviguer soit par oeuvres, soit par expressions.

Si vous vous contentez de l’afficher dans Github, vous serez certainement déçu, car le code ne s’exécute pas en ligne : il faut pour cela télécharger le notebook et être en mesure de l’exécuter sur son poste — en ayant installé préalablement Python, Jupyter et les librairies nécessaires : elles sont toutes standard et installées en même temps de que Python, sauf peut-être Graphviz, Unidecode et (certainement) SRUextraction. Il faut aussi télécharger les scripts Python liés au Notebook dont le code s’exécute de manière masquée, pour permettre au notebook de contenir très peu de code : ce sont tous les fichiers .py du dossier UnimarcLRM sur Github.
Liste des résultats
Mais vous pouvez aussi récupérer directement l’ensemble des pages de résultats, correspondant à une liste de tout le jeu de données : sur Zenodo
Récupérer les pages de résultats HTML
Une fois le ZIP téléchargé et décompressé, vous pouvez ouvrir par exemple le fichier form.html avec le navigateur, « mimer » une recherche, et obtenir une page de résultats (mais quelle que soit la recherche, ce sera toujours la même liste de résultats, avec toutes les oeuvres, ou toutes les expressions).

À suivre
Comme je le disais, j’ai plein d’autres choses à expliquer, signaler, commenter.
Mais pour l’instant, déjà, je publie le jeu de données et le Notebook (les deux sont très susceptibles d’évoluer dans les semaines à venir) et je vous laisse éventuellement les découvrir par vous-mêmes.
Notice détaillée d’expression

Bloc d’infos professionnelles en bas de notice détaillée d’oeuvre
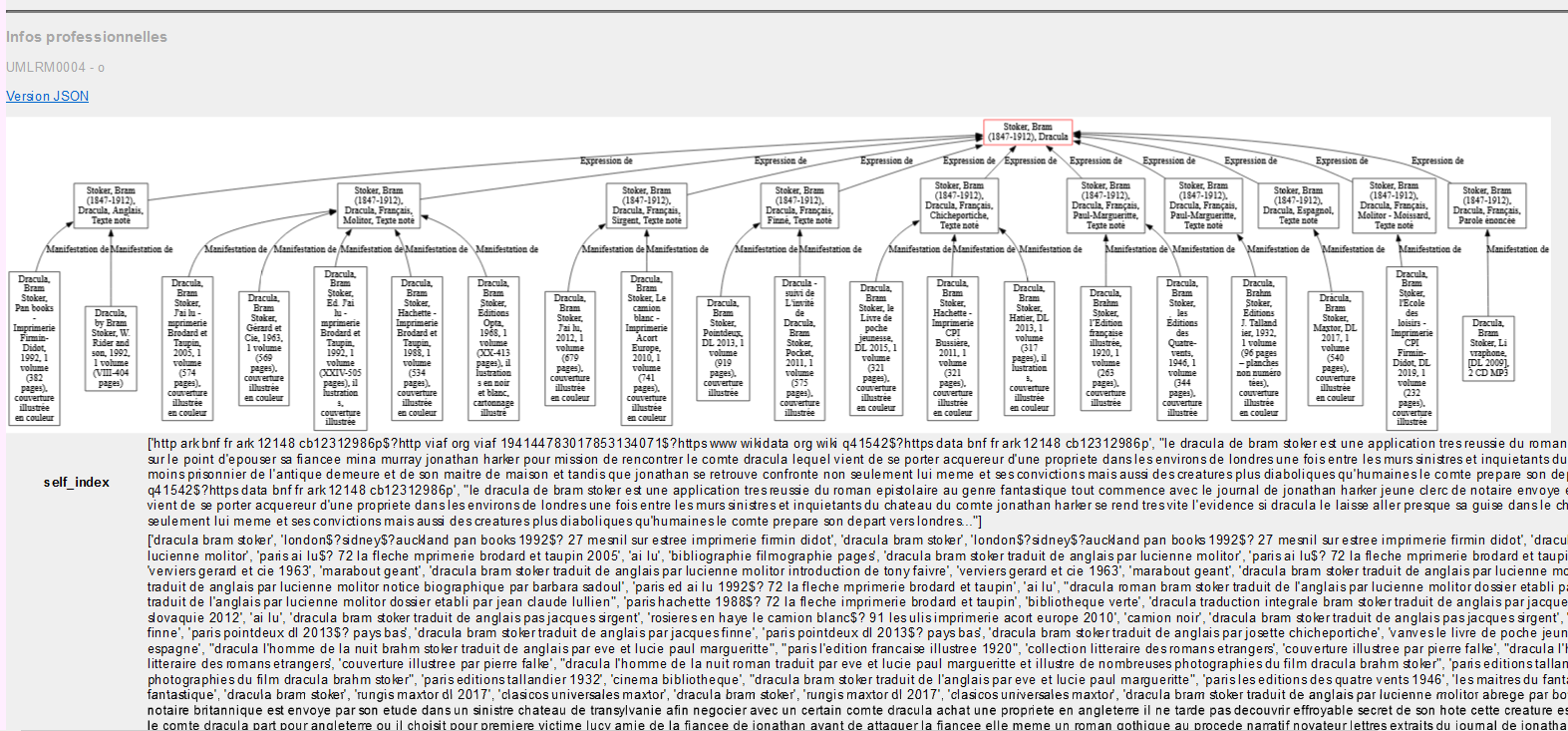
Alors, c’est très moche, je n’ai aucun bon goût ni don pour le graphisme, mais l’ensemble de la navigation est presque interactive.
Le département des Métadonnées recrute !
On recherche un ou une chef-fe d’équipe Analyse et traitement des données, adjoint-e de la cheffe de service (de 20 personnes)
C’est une équipe formidable de 10 personnes, conservateurs ou catalogueurs, qui porte le projet data.bnf.fr et la qualité des données du catalogue (avec des enjeux particuliers sur le projet de réinformatisation de la BnF, qui vise à mettre en oeuvre à échéance de 2 ans, un catalogage par entités LRM en appliquant RDA-FR). Les enjeux contiennent beaucoup d’innovation, de conduite du changement, de défis d’avenir passionnant.
Le service s’appelle « Ingénierie des métadonnées », l’équipe s’appelle « Analyse et traitement des données » — et rien que ces noms, je les trouve merveilleux !
Et l’encadrement est formidable aussi (et je ne dis pas ça parce que j’en fais partie : au contraire, ça me permet d’être d’autant mieux renseigné !).
Ah oui, sinon, d’autres bibliothèques recrutent aussi :

Après 6 mois à bloquer sur des problèmes techniques pour livrer une nouvelle version de Bibliostratus, j’ai enfin pu y arriver, et vous livrer une version 1.35.
Voici les mises à jour concernées : ils concernent tous le module blanc Alignements bibliographiques.
Télécharger Bibliostratus 1.35
Amélioration de la recherche par titre-auteur-date
Suite à une erreur dans le code, le nom de l’auteur était jusque là dans une forme non nettoyée (normalisation sur les espaces, les accents, etc.), ce qui peut empêcher certains alignements.
Les alignements sur les recherches par mot y seront donc plus nombreux.
Contrôle de date sur un alignement par ISBN
En plus du contrôle sur le titre, l’alignement est aussi contrôlé sur la date de publication (à 1 an près).
En effet il est arrivé que certains (rares) éditeurs réutilisent le même ISBN pour des rééditions du même documents plusieurs années ou dizaines d’années plus tard.
Contrôle sur le nom de l’éditeur
Depuis plusieurs années, le format en entrée de Bibliostratus imposait une colonne « Editeur » pour les monographies imprimées, sans que j’ose vraiment l’utiliser : en effet la manière de saisir l’éditeur peut être très variable d’une base à l’autre, avec des règles de saisie, des abréviations, des non-mentions, etc. très différentes.
Il semblait donc risqué de mettre en place un contrôle sur les données trouvées, par rapport aux données entrantes : on risquait de générer de nombreux faux négatif (aucun alignement trouvé, parce que « C.-Lévy » ne correspond pas à « Calmann-Lévy », ni « GF » à « Garnier Flammarion »).
Est proposé désormais un paramétrage laissé à la main de l’utilisateur, dans les préférences, permettant de mettre un contrôle de 0 (pas de contrôle) à 3 (contrôle strict)

Le contrôle sur l’éditeur ne se fait qu’à partir du moment où il y a une proposition d’alignement (faite sur une recherche par ISBN, EAN, Titre-Auteur-Date)
- 0 : pas de contrôle, les données en entrée dans la colonne Editeur ne sont pas comparées avec celles trouvée dans la notice alignée
- 1 : la valeur de l’éditeur en entrée est présente dans la notice trouvée — ou l’inverse
- Si le fichier en entrée contient « Flammarion » et la notice Sudoc/BnF contient : « Garnier Flammarion », le contrôle validera l’alignement
- Si le fichier contient « G.Flammarion », la chaîne de caractère (nettoyée) « g flammarion » n’est pas présente dans « garnier flammarion », donc l’alignement sera rejeté
- Si le fichier en entrée a une colonne vide, et que la notice Sudoc/BnF contient « Garnier Flammarion », l’alignement se fait
l’absence de valeur dans une des deux notices comparées entraîne l’absence de contrôle
- 2 : même contrôle qu’en 1. La seule différence est que s’il y a une valeur vide, ça n’annule pas la comparaison : il faut dans ce cas que pour les 2 notices aucun éditeur ne soit mentionné
- 3 : l’alignement n’est validé que s’il y a une valeur strictement équivalente de part et d’autre
- En cas de proposition d’alignement, si le fichier en entrée contient « Flammarion », l’alignement ne sera valide que si la notice trouvée contient aussi « Flammarion », mais ni « Garnier-Flammarion » ni « GF »
- si la colonne est vide d’un côté, il faut que la valeur le soit aussi dans la notice trouvée
J’ai rédigé un notebook qui donne plusieurs exemples (avec valeurs d’éditeur trouvées) où un alignement se fait avec la valeur 0, mais pas avec la valeur 1 — ou avec la valeur 1, mais pas avec la valeur 2, etc. Avec plein d’exemples sur :
- Editions du Seuil <->Seuil
- British Library <-> The British Library
- Librarie Académique Perrin et Cie <-> Perrin
- Ernest Flammarion <-> E. Flammarion
Sachant qu’il y a plein d’autres cas aussi où, naturellement, le contrôle sur l’éditeur permet de lever des erreurs.
En tout cas vous aurez désormais pour faire vous-même votre choix, y compris en comparant les résultats avec les différents niveaux, selon votre corpus, vos règles de catalogage, la période des documents à aligner, etc.
