LibX et proxy : un autre angle d’attaque
Comme indiqué ici, il faut présenter à l’internaute l’outil sous une forme brève et aguichante. Même si l’outil proposé permet bien plus que la phrase de présentation.
Sur LibX, j’avais proposé de broder sur le thème : Trouvez nos livres sans devoir passer par le catalogue. Parce que c’est vraiment une contrainte pour le lecteur de passer par nos opac.
De la même manière, on forme actuellement nos étudiants aux A-Z (que ce soit SFX, AtoZ d’Ebsco ou un autre outil), en leur disant : depuis chez vous, si vous passez par Google Scholar, vous n’aurez pas accès aux articles parce que votre IP n’est pas reconnue. Donc si vous avez trouvé un article intéressant, il faut repasser par le catalogue pour cliquer sur le lien « Accès distant ».
Ou quelque chose comme ça.
J’ai trois commentaires à faire là-dessus :
- c’est vrai, on est obligé de passer par le catalogue des revues en ligne.
- c’est frustrant, voire pénible.
- cette démarche est nécessairement oubliée par une partie de nos lecteurs.
Si vous avez un proxy, LibX permet d’évacuer cette démarche. Elle vous permet de dire à vos lecteurs : Vous pouvez enfin passer de Google Scholar à l’article sans faire un détour par chez nous.
Je sais, ça brutalise votre sens de la méthodologie documentaire. Mais ayez tout de même un peu pitié de vos lecteurs.
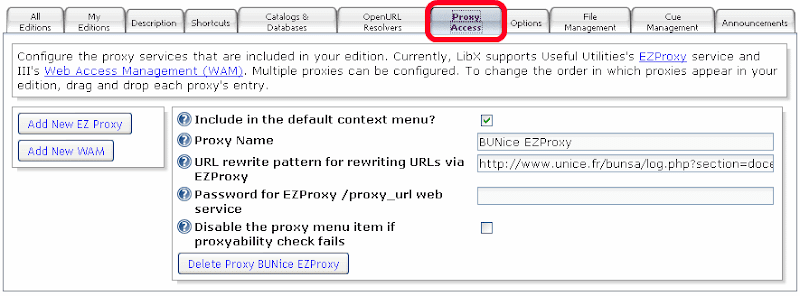
Comment ça se remplit ?
Remarque : ça marche avec EZProxy. J’ai buggé en testant avec Biblio-PAM (mais vous pouvez essayer tout de même). D’après l’interface LibX, ça marche aussi avec WAM d’Innovative Interfaces, mais je n’ai pas testé.
Cochez la première case (je vous en reparlerai ensuite).
Mettez un nom à ce proxy. Un joli nom compréhensible par vos lecteurs, de manière à ce qu’ils comprennent à quoi correspond la fonction et qu’ils aient envie de cliquer dessus. Par exemple : « Accès distant »
Pour l’URL, la bulle d’aide est assez claire :
Par exemple, si vous utilisez l’URL http://ezproxy.lib.vt.edu:8080/login?url=http://www.sciencedirect.com quand vous voulez proxyfier l’accès à http://www.sciencedirect.com, alors la valeur à indiquer est : http://ezproxy.lib.vt.edu:8080/login?url=%s
Comment on s’en sert ?
Désormais, si vous êtes sur n’importe quelle page, un clic droit donne dans le menu contextuel (d’où le coche de la première case dans la configuration) :

Donc désormais on peut arriver sur un article de n’importe quelle manière, et basculer en mode proxyfié d’un simple clic.
Remarques :
- Evidemment, cela ne nous garantit pas que la bibliothèque est déjà abonnée, mais c’est tout de même pas mal, non ?
- Si l’URL n’a pas été déclarée auprès du proxy, on retombe sur l’URL normale non proxyfiée.
<update>Il faudra que je vous parle de la capacité de Zotero à exploiter la proxyfication (et merci à Perrine pour cette info)</update>
Trackbacks
Commentaires fermés

Bonjour
Je suis administrateur systèmes et réseau. Je m’occupe de l’aspect
proxies pour une bibliothèque de mathématiques. Nous utilisons
actuellement un système de proxies.
Je ne comprends pas bien votre post. Vous me semblez mélanger deux
notions mais c’est peut-etre parce que dans mon milieu vos expressions
ont un autre sens :
– vous voulez que le lecteur accède à une revue depuis n’importe où
sur la planète, via une authentification, sans passer par votre
interface web institutionnelle de consultation (je suis d’accord
avec ce que vous dites jusqu’à la première copie d’écran de votre
post) : oui dans mon milieu on appelle cela du « proxy »
– le lecteur passe par une interface web de la bibliothèque qui elle,
après authentification du lecteur, interface web, se connecte sur le
site de l’éditeur et consulte la revue et réécrit les pages web pour
que le lecteur au cours de sa navigation web passe toujours par
l’interface web de la bibliothèque (en gros la session est captive
de l’interface web) (c’est la partie « Comment ça se remplit » de
votre poste) : dans mon milieu, on appelle cela du « reverse-proxy »
Est-ce que je me trompe ?
Je précise que je ne connais pas LibX, EZpro, ni Biblio-PAM.
Je suis aussi étonné par la copie d’écran du menu du navigateur.
De quel navigateur s’agit-il ? Je ne comprends pas bien ce qu’est la
dernière ligne.
Pour donner de l’eau à votre moulin, voici ce que nous faisons ici et
les défauts que nous avons constatés :
– nous avons deux machines de proxies qui gèrent des abonnements. On
dira une machine A pour les abonnements « bleus », une machine B
pour les abonnements « rouges »
– nous indiquons aux utilisateurs de configurer spécialement leur
navigateur via un fichier « .pac » à charger
L’utilisateur surfe ensuite sur internet. L’URL de ce qu’il consulte
est comparé au contenu du fichier « .pac ».
Si l’URL consulté répond à un motif du fichier « .pac », on utilise la
machine A ou B selon ce qui est associé au motif reconnu et la
consultation du lecteur passe alors par la machine A ou B qui est
reconnue de l’éditeur et le lecteur accède à sa revue en full-text.
Si l’URL consulté ne répond pas à un motif, la consultation est
directe du poste du lecteur au site de l’éditeur et il advient ce
qu’il advient. Amen.
Le problème dans tout cela est la différence entre le site de
consultation de l’éditeur (le point de départ) et le site de la
plateforme de téléchargement de l’éditeur pour récupérer le PDF du
full-text (le point d’arrivée). Vous pouvez très bien entrer par
exemple par un URL du type DOI et finir sur un truc
http://projecteuclid.org/… Et au niveau du fichier « .pac », il
faut que cela soit l’URL « http://projecteuclid.org/… » qui soit
déclaré.
La difficulté est donc, pour moi mais je suis un pur informaticien,
cette différence de fait entre l’entrée de la revue qui est celle que
communique l’éditeur et la face cachée qui est le téléchargement du
document de la revue que l’éditeur ne communique pas. C’est le gros
défaut du proxy à mon gout.
D’où notre idée de passer à une solution du genre « reverse proxy » :
une interface web présente tous les titres auxquels nous sommes
abonnés et l’utilisateur clique sur le titre qui l’intéresse. Le
serveur web se connecte alors sur le site de l’éditeur et ramène les
pages qu’il réécrit de façon à ce que si l’utilisateur clique sur un
lien, la consultation du lien repasse à nouveau par le serveur
web.
L’intérêt, c’est que même si l’éditeur donne un point d’entrée du type
DOI et que le téléchargement arrive sur un autre URL, comme toute
cette navigation web provient du serveur déclaré chez l’éditeur, ce
trafic est autorisé par l’éditeur.
Autre intérêt : nous n’avons pas le casse-tête du fichier « .pac » du
proxy à gérer.
Autre intérêt : l’utilisateur n’a rien à configurer sur son navigateur
(il n’a pas à déclarer le fichier « .pac » quelque part). Il
s’authentifie sur la page web et l’interface web de la bibliothèque se
charge de tout après.
Donc en gros, j’avais pour idée de faire ce que vous dites n’être pas
pratique…
Si vous voulez en discuter…
Cordialement,
Thierry Besançon
@Thierry Besançon : première réponse : quand je parle de proxy, dans un contexte d’accès distant aux ressources, c’est toujours un reverse proxy.
Les bibliothèques ne mettent jamais en place de proxy simple, ceux-ci sont toujours reverse.
Pour le reste, je relirai calmement votre long commentaire, dont je vous remercie, et je m’efforcerai de préciser.
Rebonjour
Entretemps, j’ai découvert libx. Je n’en ai pas lu le fonctionnement technique par contre faute de temps (je ne m’occupe pas exclusivement de bibliothèque) mais cela va venir. En tout cas, merci de votre post original car il va alimenter notre réflexion indubitablement.
Thierry
Avez-vous vu passer le 1er billet sur LibX https://bibliotheques.wordpress.com/2009/10/06/libx-premiere-approche/ ?
Ou peut-être n’est-ce plus nécessaire désormais (puisque vous êtes informaticien !) ?
Cela m’intéressera de savoir ce que vous avez mis en place, si vous avez le temps de repasser par ici pour le raconter 🙂
J’ai perdu le fil puis je l’ai retrouvé après quelques autres taches
système à remplir. A nouveau, je dois lire la doc de libx car de mon
point de vue, il s’agit de construire une extension libX pour la
bibliothèque avec laquelle je collabore. Si je mène le projet au bout,
je vous donnerai mon tutorial de création de plugin libx à ce blog.
Sinon ne pensez-vous pas que l’installation d’un plugin est « lourd »
par rapport à l’utilisation d’un portail reverse proxy ?
Il faut maintenir le plugin à jour par rapport aux évolutions de FF ou
IE ; le navigateur APPLE SAFARI — même si c’est une !@#$%^&*()_+ à
mon avis — est ignoré ; etc. J’ai des utilisateurs éparpillés dans
le monde (dixit le chercheur : « Je suis depuis deux mois dans la
ville de Lubec de l’état de Maine au U.S.A. ») et le support d’une
solution autre que le reverse proxy est difficile a priori. Alors le
plugin qui est un produit plus complexe que ma solution de proxies
(insatisfaisante), ne soulève pas en moi un flot d’optimisme…
Des gens de ce blog ont-ils un retour d’expérience sur l’appréciation
du public sur ces plugins libx ?
Thierry
Je pressens que nous ne parlons pas des mêmes choses.
Je n’ai pas trop de temps en ce moment, mais l’idée de base pour l’utilisation du plugin est très simple : actuellement, pour accéder à un article en accès distant (de chez lui), le chercheur, qui a trouvé l’article sur une base et s’est trouvé bloqué par l’accès, doit revenir au site de la bibliothèque, retrouver la revue, cliquer sur « Accès distant » (URL proxyfiée) et revenir sur la plate-forme de la revue pour y rechercher de nouveau son article du début.
Avec ce plugin, il arrive sur l’article depuis n’importe où. En mode non proxyfié (sa navigation normale, quoi !).
Au lieu de devoir repasser par le site de la bibliothèque (etc.), il a installé LibX auparavant, il fait un clic droit et bascule sur le même article mais en mode proxyfié.
Trop cool pour lui !
Cela dit (mais il faudra que je creuse un peu pour faire un autre billet) sur l’objectif de simplifier la démarche de l’internaute, Zotero apporte peut-être une réponse encore plus simple (merci @phelly).
Affaire à suivre…
LibX implique un reverse proxy installé par la bibliothèque sur ses serveurs. Quand la bib paramètre LibX (pour le proposer à ses lecteurs), elle y indique les informations sur son reverse proxy.
Les màj du plugin (liées aux évolutions de Firefox plus qu’au changement de reverse proxy), je suppose, se font « automatiquement » sur le modèle des autres extensions.